Processes, threads, parallelism, concurrency
Cílem každé aplikace je pracovat co nejrychleji a využít přidělené prostředky, jako je procesor a paměť, co nejoptimálněji. Ve svých aplikacích můžeme běžně najít místa, která jsou buď náročná na výpočetní výkon (CPU-bound) nebo na komunikaci (I/O-bound).
- Pokud náš program komunikuje s databází, cizím API nebo souborovým systémem, procesor se v tu chvíli nudí (I/O-bound).
- Pokud provádí matematické výpočty nad daty, zpracovává obraz či text, zaměstnává výrazně procesor (CPU-bound) a měli bychom tudíž použít více jader, pokud je máme k dispozici.
Proces je úloha spuštěná na úrovni operačního systému. Pokud spustíme python script, spustíme tím nový proces s vlastními přidělenými zdroji a s jedním hlavním vláknem. Pokud máme více procesorů, může v jednu chvíli běžet více procesů zároveň. V tuto chvíli můžeme začít hovořit o pojmu parallelism.
Paralelismem rozumíme situaci, kdy nám skutečně běží více úloh současně. Pokud však máme k dispozici jenom jedno procesorové jádro, nemůžeme o paralelismu hovořit, protože, ačkoliv to vnějšímu pozorovateli tak připadá, v jednu chvíli na procesoru běží pouze jedna úloha a jejich rychlé přepínání působí dojmem, že běží zároveň.
Tady si můžeme zavést pojem concurrency - tedy schopnost “podělit se o strojový čas” s ostatními úlohami.
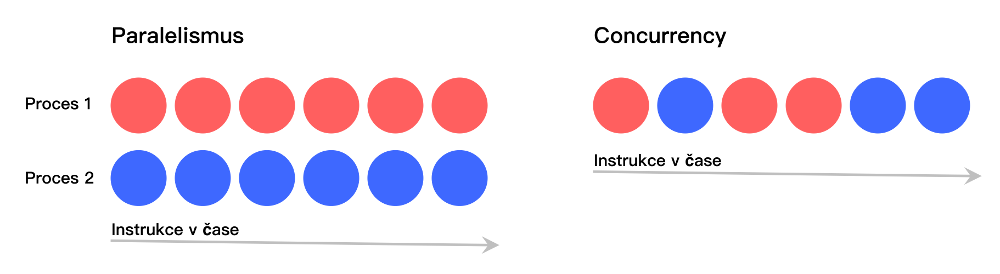
Pokud máme výpočetně složitou úlohu a k dispozici procesor s více jádry, bývá zvykem vytvořit si v aplikaci více vláken. Každé vlákno zpracovává část úlohy a dílčí výsledky se pak spojí dohromady. Ve výsledku by se pak celkový čas výpočtu měl zkrátit poměrově o tolik, kolik máme k dispozici jader. Jenže v Pythonu je to, bohužel, jinak (v případě CPythonu). Kvůli tomu, jak funguje v Pythonu garbage collector, existuje globální zámek nad sdílenými zdroji (Global Interpreter Lock - GIL) a i když máme k dispozici více procesorových jader, Python interpreter dokáže pracovat vždy pouze s tím, ve kterém je spuštěn hlavní proces. To znamená, že i když si vytvoříte více vláken, nikdy nejsou spuštěny paralelně. Vždy se mezi nimi přepíná, což nám paradoxně zabraný procesorový čas ještě zvýší.
Praktická ukázka
Nepíšeme jednoduchý program, který vygeneruje list náhodných čísel. Nejdřív bez vláken nebo subprocesů.
import random
def main():
generate = 100_000_000
output = []
for _ in range(generate):
output.append(random.random())
print(len(output))
if __name__ == "__main__":
main()
Pomocí systémového nástroje time zjistíme, jak dlouho takový program běží. V tomto případě je to na mém počítači necelých 20 s.
$ time python basic.py
100000000
real 0m19.848s
user 0m15.221s
sys 0m4.207s
Zkusíme běh aplikace a vygenerování listu náhodných čísel urychlit pomocí vláken. Teoreticky, pokud máme k dispozici minimálně 2 jádra a vyrobíme 2 vlákna, která se spustí zároveň a vygenerují právě polovinu náhodných čísel, měl by se program urychlit zhruba 2x. Zkusme to.
import random
import threading
def generate_random_numbers(output_array, n):
for _ in range(n):
output_array.append(random.random())
def main():
generate = 100_000_000
output = []
t1 = threading.Thread(target=generate_random_numbers, args=(output, generate//2))
t2 = threading.Thread(target=generate_random_numbers, args=(output, generate//2))
t1.start()
t2.start()
t1.join()
t2.join()
print(len(output))
if __name__ == "__main__":
main()
$ time python threads.py
100000000
real 0m21.119s
user 0m15.410s
sys 0m4.837s
Všimněme si teď dvou důležitých věcí. Běh programu trval zhruba stejně dlouho jako bez vláken a zároveň jsme si dokázali, že všechna vlákna sdílejí stejný paměťový prostor, jinak bychom nedostali na výstupu list o velikosti 100 000 000.
💡 Na tomto místě bych okrajově zmínil jednu věc: kvůli preemptivnímu přístupu k přepínání vláken, nikdy nevíte, při jaké instrukci k přepnutí dojde. V tomto případě je funkce append() atomická instrukce, takže na výstupu získáme opravdu vždy velikost listu 100 000 000. Kdybychom však pomocí více vláken chtěli inkrementovat počítadlo, třeba do této hodnoty, nemuseli bychom po ukončení běhu vždy získat stejný výsledek a to kvůli tomu, že inkrementace čísla není atomická instrukce.
K čemu se tudíž v Pythonu vlákna hodí, když nám nepomohou urychlit náš CPU-bound program? K tomu, že nám spuštěná subroutine neblokuje hlavní smyčku programu.
Pokud bychom skutečně chtěli náš CPU-bound program nějakým způsobem urychlit, můžeme místo modulu threading sáhnout po modulu multiprocessing. Jak je naznačeno v příkladu níže, pomocí něj můžeme vytvořit podprocesy, které mají přiděleny vlastní zdroje, třeba právě vlastní jádro.
import random
import multiprocessing
def generate_random_numbers(output_array, n):
for _ in range(n):
output_array.append(random.random())
def main():
generate = 100_000_000
output = []
p1 = multiprocessing.Process(target=generate_random_numbers, args=(output, generate//2))
p2 = multiprocessing.Process(target=generate_random_numbers, args=(output, generate//2))
p1.start()
p2.start()
p1.join()
p2.join()
print(len(output))
if __name__ == "__main__":
main()
$ time python processes.py
0
real 0m10.495s
user 0m18.172s
sys 0m1.994s
Jak si můžete všimnout, tak to, že má každý proces oddělené zdroje, je dvousečná zbraň. Na standardní výstup se nám vrátilo, že velikost listu output je 0. Pokud mezi podprocesy potřebujeme sdílet nějakou informaci, je potřeba sáhnout po sdílené paměti (shared memory). Jenže pozor, přístup ke sdílené paměti je zase časově náročná operace, takže je potřeba ho využívat s mírou.
V této první části věnované asynchronnímu pythonu jsme se zabývali vlákny a obecně preemptivním přístupem konkurenčního zpracování kódu. V další části se budeme věnovat knihovně AsyncIO a kooperativním přístupem.